DTO & DAO
- 2022 年 03 月 19 日
- 架构
DTO 描述
在编程领域,数据传输对象(DTO)是在进程之间传输数据的对象。
使用它的动机是进程之间的通信通常通过远程接口(例如,Web 服务)完成,其中每次调用都是昂贵的操作。因为每次调用的大部分成本都与客户端和服务器之间的往返时间有关,所以减少调用次数的一种方法是使用一个对象(DTO)来聚合数据已由多个呼叫转移,但仅由一个呼叫提供服务。
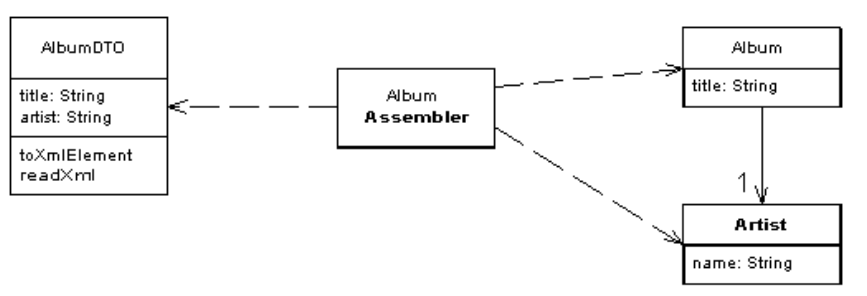
DTO的一个例子
需要员工的姓名和照片才能进入您的公司,您需要为匹配提供该数据,但是并不需要提供您在数据库中拥有的员工的其他信息,DTO只能传输所需要的信息。如图示:
DAO 描述
在软件中,数据访问对象( DAO ) 是一种为某种类型的数据库或其他持久性机制提供抽象接口的模式。
DAO 提供了一些特定的数据操作,而不暴露数据库的细节。
DAO 使用场景例子
想象一下,您拥有一家成功的公司,该公司已收到为 2 个不同客户开发应用程序的合同。两个客户端的应用程序规格几乎相同。两个客户端都使用 SQL 数据库管理数据,但一个公司使用专有数据库,另一个使用开源替代方案,这意味着您的应用程序的持久层将需要以两种不同的方式实现。此外,随着新客户端的出现,可能需要额外的实现。在这种情况下,使用数据访问对象模式将确保访问任何不同的后端数据库所需的正确数量的抽象和封装。
参考文献
DDD 仓储
- 2022 年 03 月 19 日
- 架构
了解仓储
Repository 是仓库管理员,领域层需要什么东西只需告诉仓库管理员,由仓库管理员把东西拿给它,并不需要知道东西实际放在哪。
用于协调领域和数据映射层,两个关键字领域和数据映射层,这里面的领域是指领域模型(实体和值对象),这是桥的一头,另一头就是数据映射层,也就是我们常说的 ORM 工具
仓储是永久保存领域对象的仓库;在DDD中引入这个概念,是为了隔离业务领域和不同的数据库。
一个对象可以保存到关系数据库,也可以保存到NoSql中;具体的保存形式与数据结构的变化不会对领域对象的实现产生影响。
在DDD中,仓储模式替代了DAO;
仓储与DAO的主要区别:
- 仓储主要是为了保证聚合根对象的加载和保存,同时兼顾一些实体的直接访问;
- DAO没有这些约束;没有数据所有权概念,没有聚合概念;是数据持久化的接口;
实现仓储
仓储的实现方式
实现仓储可以从两个方式进行:面向集合与面向持久化
面向集合的设计,此时领域当仓储是无限大一个集合,所以仓储只具有集合的概念接口:
- Add
- Remove
- Get
面向持久化的设计,则是将仓储更像是DAO,作为领域对象的持久化过程,此时接口:
- Save
- Delete
- Commit
同一个聚合实例不允许多次添加到仓储中
这个一点,是由于聚合的唯一性,以及仓储的集合特性所共同决定的(在一个集合中不能存在两个相等的对象)。
在仓储的集合设计中,一个对象在更新后,不需要重新执行Add操作,而是在更新时直接作用到这个对象上。
因为仓储中Get出来的对象是对象的引用。
仓储实现方法返回类型建议为void
func Add(TAggregateRoot aggregateRoot) {}
那么如何判断该聚合实例成功添加到了仓储中呢?我们可以自定义一个异常信息,抛出这个异常。
最好不要使用addAll() 和removeAll()方法
建议使用循环调用 Add和Remove方法
聚合中删除聚合实例的含义
在领域驱动设计中,不存在对象删除的说法,正确的表达是,将聚合实例标记为失活的(disable),不可用的(unuseable);也就是所最好不要再仓储中出现delete;至于数据库具体持久化中是否进行delete,就不在仓储的设计中了。
仓储在软件分层中的位置
仓储接口的定义放在了与聚合相同的包中,而仓储的实现类放在基础设施层中(目前我们的方法)。
仓储调用在分层架构中的位置
目前的想法是仓储应该放在领域服务中,在应用服务中只应该看到和传递数据。
参考文献
Python Lint 错误
- 2022 年 03 月 15 日
- Python
E1138 unsupported-delete-operation
对于一个类如果其具有object.delitem(self, key)实现,那么在进行类对象操作时,就可以使用del关键字执行调用__delitem__实现的操作。 例如:
class Foo:
def __init__(self, numbers):
self.numbers = numbers
def __delitem__(self, index):
self.numbers.pop(index)
foo = Foo([1,2,3])
del foo[0]
print(foo.numbers)
------------------
[2,3]
E1139 invalid-metaclass
对于一个类在其创建时,指定metaclass时,指定的元类必须是有效的。
元类有效的意思是:元类本身是type的子类,其作用是跟type一样用于创建class。
在解析器内部,一般的通过class关键字定义的类,是会转化为type进行创建的。
type创建类的方法:
def fn(self, name='world'):
print('Hello, %s.' % name)
Hello = type('Hello', (object,), dict(hello=fn))
Hello().hello("sun")
-----------
Hello, sun
type()的三个参数分别是:类的名称,父类的集合tuple,这个类的方法名和对应的方法实现绑定操作。
那么类在定义时如果指定metaclass,意思就是这个类的创建是使用这个指定的metaclass(type子类)来进行创建。
- 类的多重继承会继承这个metaclass,即认为这些类都是指定了metaclass的
- 所有指定metaclass的类,都是由这个metaclass的__new__()来创建
- 一般元类的命名最后都是以*Metaclass结尾的
例如下面这个例子,给User这个类指定元类,并且在元类中为User这个类在创建时,增加一个add方法:
class UserMetaclass(type):
def __new__(cls, name, bases, attrs):
attrs['add'] = lambda self, value: self.append(value)
return type.__new__(cls, name, bases, attrs)
class User(list, metaclass=UserMetaclass):
def __init__(self, users):
for u in users:
self.append(u)
u = User(["sun", "ming", "hui"])
u.add("Julien")
print(u)
----------------
['sun', 'ming', 'hui', 'Julien']
E1140 ubhashable dict key
dict类型中元素的key值必须是hashable的,具体hashable的含义是:值对象在生命周期内是不变的,并且具备相等比较能力。
- 值对象具有 hash()方法
- 值对象具有 eq()方法 或者 cmp()方法
- 基础值类型中,list、dict、set都是不可hash的
- 没有实现hashable对象方法的类对象,也是unhashable的
参考
- 使用元类 — 廖雪峰的官方网站
面向切面编程
- 2022 年 03 月 14 日
- 软件设计
概念
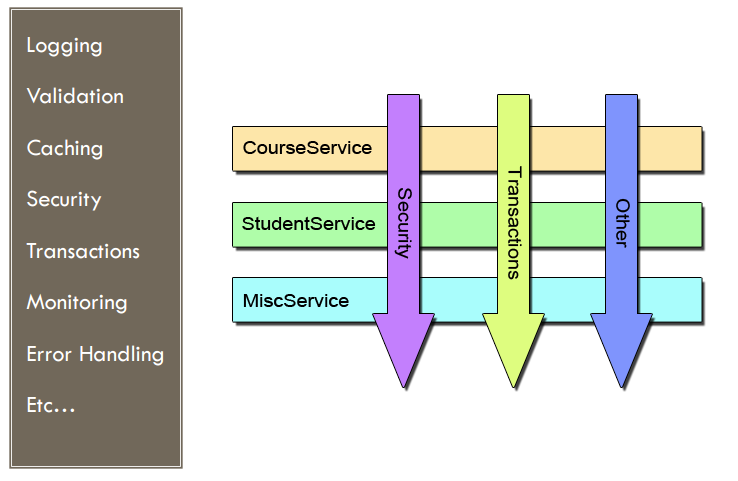
AOP(Aspect-Oriented Programming, 面向切面编程,又称剖面导向程序设计)是计算机中的一种程序设计的思想,旨在将横切关注点与业务主体进行进一步分离,提高代码的模块化程度。
举个例子:那些url对于处理中都有鉴权相关代码时,一般就需要在每个url的处理中加上鉴权相关的调用处理,此时这个业务代码就已经跟鉴权处理产生了耦合。
如果要解除这个耦合,那么就需要将这些业务处理之外,但是工程上需要的(日志记录、性能统计、安全控制、异常处理等)通用处理的代码从业务对象代码中独立出来。达到这些通用处理变更时,业务无需感知的目的。
上面的逻辑中,业务对象的设计可以是基于业务进行的OOAD设计出来的。而独立于业务之外,需要跟业务配合执行的通用功能代码的解耦设计,有一种方法就是面向切面编程了。
术语
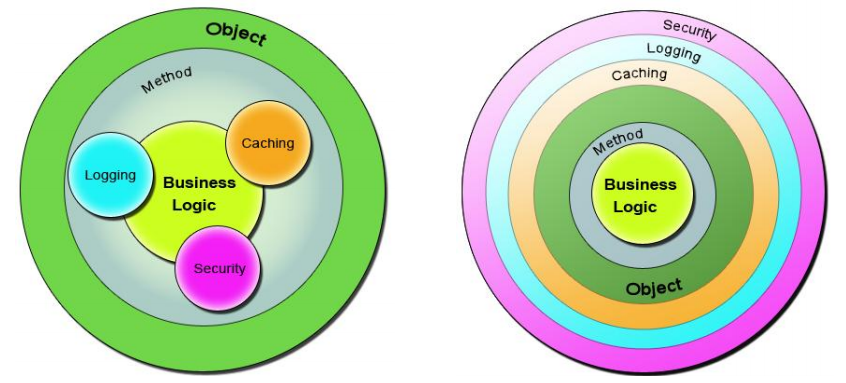
不是很严谨的一个借喻:
切面 Aspect
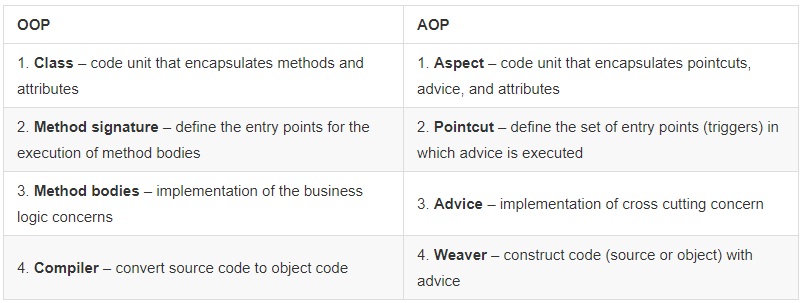
连接 通知(adivces) 和 切入点(pointcuts);决定在哪里执行什么。
连接点 Join point
业务流程在运行过程中需要插入切面的具体位置,可以是程序中的任何可识别的地方。
切入点 Pointcut
连接点的集合,并且定义通知应该切入到哪些连接点上,不同的通知通常需要切入到不同的连接点上
通知 Advice
在执行到切入点之前,实现的before、after等逻辑。包括:前置通知(Before)、后置通知(AfterReturning)、异常通知(AfterThrowing)、最终通知(After)和环绕通知(Around)五种。
目标对象 Target
被一个或者多个切面所通知的对象。
代理对象 Proxy
将通知应用到目标对象之后被动态创建的对象。可以简单地理解为,代理对象为目标对象的业务逻辑功能加上被切入的切面所形成的对象。
切入/织入 Weaving
将切面应用到目标对象从而创建一个新的代理对象的过程。这个过程可以发生在编译期、类装载期及运行期。
Go语言AOP库
有一个库的使用说明看起来思路不错,但是无法正常运行:https://github.com/gogap/aop